Building towards a Flexible Dynamic Autoscaling Architecture with Ray / EKSRay - Part 2
In our previous post, we explored the fundamentals of RayClusters and RayJobs within EKSRay. Cambridge Mobile Telematics’ (CMT) in-house data science platform EKSRay, built upon Amazon EKS, Kubernetes, KubeRay, and a custom CLI. EKSRay is designed to harness Ray’s powerful parallel computing capabilities for large-scale data processing tasks.
EKSRay enables the creation of a unified cluster configuration that accommodates diverse resource requirements, from CPU-intensive Extract, Transform, and Load (ETL) tasks to memory-intensive data transformations and GPU-enabled model training and inference. This configuration allows users to precisely tailor resource allocation, minimize idle times between pipeline stages, and maximize cluster compute efficiency. The EKSRay CLI further streamlines this process by reducing the traditional overhead associated with scaling and cluster management, allowing data scientists to focus more on innovation and less on infrastructure challenges.
This article aims to elaborate on the above in more detail, by exploring CMT’s implementation of Resource-based Parallelism and autoscaling using Ray on EKSRay. Specifically, we will examine the following three techniques:
- Custom Resource Tagging for RayCluster Resources: Assigning specific labels to worker machines to optimize resource allocation and scheduling.
- Formation of Custom Placement Groups (PGs): Using these labels to create groups of compute resources that can be scheduled together for enhanced performance.
- Gang Scheduling of Cluster Resources: Coordinating the simultaneous execution of related tasks across multiple processors to improve efficiency.
Collectively, these features aim to provide a Flexible Dynamic Autoscaling Pipeline, and facilitate hands-off parallelism, enabling efficient scaling of complex workloads. To illustrate these concepts in practice, we also present a concrete example of their application in our Event Detection Modeling pipeline.
While our examples focus on EKSRay, the principles discussed are applicable to other Ray-based environments, especially as the Ray community continues to evolve and introduce new features. Our goal is to share insights from our EKSRay implementation experiences that can be replicated or adapted to suit various platforms supporting this style of architecture.
Resource-based Parallelism with Ray
In distributed computing, effectively managing and allocating resources is crucial to optimize performance and scalability. Ray addresses this need by providing mechanisms to define and utilize custom resources, enabling precise control over task scheduling and execution. This section explores how Ray’s resource-based parallelism facilitates efficient workload distribution and dynamic autoscaling within EKSRay.
Custom Resource Tagging for RayCluster Resources

Ray (and EKSRay) support “custom resource tags” through cluster configuration. These tags act as identifiers for each worker machine and include the machine’s specifications. They enable two critical capabilities:
- Worker machine tagging that labels each worker in a a RayCluster so that Ray recognizes its resource profile (e.g., CPU, GPU, memory).
- Cluster resource awareness that makes the entire cluster (including autoscaled resources) visible to Ray, ensuring tasks are scheduled on the right machines.
Example: Cluster Provision + Auto-Tagging
Here is a simple example of how these tags work, in a practical scenario. We need to spawn a cluster that needs the following components:
- CPU Workers:
r-8xlarge - GPU Workers:
g4dn-8xlarge
We want to have a certain “minimum” (always active) vs. “maximum” (the max no. of workers which can be provisioned after autoscaling), we can have a config as follows to depict this cluster requirement:

Once we spawn a cluster with the above specifications, we then, as part of each worker’s environment variables, receive a full description of cluster resources, including potential-upscaled resources. This information is disseminated through the cluster as shown below:

Here, tags like WORKER_R_8XLARGE and WORKER_G4DN_4XLARGE become visible to the RayCluster, along with the machines’ specifications and autoscaling limits.
With these resource tags, you can directly request specific machines and resource types in your Ray code. For example:

In the above example, we are able to ask Ray to do the following:
- Execute a parallelized ray-task “
square_num” using the specific machine type “WORKER_M_16XLARGE” - Only use specific CPU/GPU/Memory resources from the machine-type to execute these tasks
This level of customization is valuable when you have multiple machine types in a single cluster—for instance, CPU-intensive tasks on large CPU nodes and GPU-specific tasks on GPU nodes. Ray and EKSRay can also spin up or down additional machines of the requested type as needed, minimizing idle costs.
Formation of Custom Placement Groups (PGs)
While the direct specification of Custom-Resources outlined above works well with simpler use-cases, this approach hits a wall when the requirements become more complicated. Some workloads require more advanced scheduling control and management. This is where Ray’s Placement Groups (PGs) come in, which lets you:
- Group compute resources of various machine-types into a single “unit” for scheduling flexibility
- Scale up or down a group of machines before or after specific tasks
- Precisely control how many compute bundles (CPUs, GPUs, memory) you make available
- Track and manage the placement group independently in the Ray ecosystem
Placement Groups become even more powerful when combined with custom resource tags and the resource specifications described above.
Let’s go over a specific example of how one might do this. Given our earlier example for a RayCluster, we can pull the exact cluster-specifications from any machine or location within the RayCluster with:
- Retrieve Worker Specifications:

This segment accesses environment variables to obtain detailed specifications of worker nodes in the RayCluster. By retrieving configurations such as WORKER_R_8XLARGE and WORKER_M_16XLARGE, you can programmatically understand the resource capacities (e.g., CPU, memory) of each worker type.
- Build the PG (Placement Group) Bundles:

Here, the code constructs resource bundles that define the allocation of resources for tasks within the cluster. Utilizing the PlacementGroupSchedulingStrategy from Ray, it specifies the number of CPUs, memory, and custom resources required for each worker type. By creating these bundles, you can ensure that tasks are scheduled on nodes with appropriate resources, optimizing performance and resource utilization.
- Spawn the Placement Group:

This final segment of the code initializes a placement group using the previously defined resource bundles. The placement_group function in Ray creates the group with a specified strategy, such as “SPREAD”, which distributes tasks evenly across available nodes to balance the load.
A lot of this can be abstracted into helper-functions which are available via existing repositories utilizing EKSRay. We can control a number of parameters with this approach such as:
- Fine-grained resource utilization for your cluster
- Configurable parallelism via bundling and scheduling strategies
- Explicit control over when and how these resources are allocated or deallocated
Because Ray (and KubeRay) are rapidly evolving, the capabilities for advanced scheduling and resource-based parallelism continue to expand. These features make Ray adaptable to specialized resource requirements, and they scale effectively as your workloads grow in complexity.
Gang Scheduling of Cluster Resources
An extension of Placement Groups (PGs) in Ray is the ability to gang-schedule tasks. Gang scheduling ensures that a set of tasks or actors only starts when all the required resources are available at the same time. If those resources cannot be allocated together, none of the tasks in the group execute. This is especially important for applications needing coordinated execution across multiple parallel workers—such as ETL processes that require synchronized parallel operations, or distributed training and tuning with Ray Train and Ray Tune.
Example: Gang Scheduling With a Placement Group
In the earlier example, we derived a Placement Group (PG) and turned it into a single bundle- for demonstrating gang-scheduling, for simplicity let us consider a simpler set of worker-machines and bundles

This creates a group with 2 bundles, each using a single CPU from the r-8xlarge and the m-16xlarge workers in our cluster. The Custom Resource tags such as "WORKER_M_16XLARGE": 0.01 indicate this resource can be re-used again in subsequent bundles (i.e. in this example, a single “bundle” is not using up all the resources of that worker machine).
Here is an example of gang-scheduling of a simple Ray-task:
This breaks down into the following steps:
- Form a Placement Group with explicitly defined resource bundles (two bundles, each using one CPU from a different worker type).
- Wait for the Bundles to be ready, which also handles any autoscaling needed.
- Specify Per-Bundle Tasks by setting
bundle_indexto tie each task to a particular worker type (e.g.,r-8xlargeorm-16xlarge). - Gang-Scheduled Execution means these tasks do not start until all required resources (across both bundles) are available simultaneously, ensuring coordinated and consistent performance.
This approach becomes especially valuable in scenarios where certain resources are limited or expensive, such as high-end GPU nodes. It ensures you do not begin a task without guaranteeing the availability of all necessary resources—helping you avoid partial allocations and potential bottlenecks.For more in-depth exploration of Ray’s scheduling mechanisms, including advanced scheduling strategies and best practices, we highly recommend delving into the official Ray-scheduling documentation (which we found quite enlightening when designing our pipelines) and other related community resources.
Bringing It All Together: Flexible Dynamic Autoscaling Architecture
Now that we have introduced and established a range of resource-based parallelism capabilities with Ray, we can now start connecting them to the crucial task of constructing a flexible and dynamically scalable orchestration pipeline, minimizing idling costs and maximizing resource-efficiency.
Using the EKSRay platform, we can now combine these techniques into one unified configuration for executing large-scale pipelines without requiring multiple separate clusters or extensive manual oversight of resource allocation. Below is an overview of how we achieve this consolidation:
- Single Cluster Definition
We create a single RayCluster, consisting of a single head node (serving as the driver machine) and multiple worker types with different resource profiles. This unified approach ensures that all tasks within the pipeline can be performed in the same environment, removing the need for duplicated cluster setups or additional overhead.
- Hybrid Worker Machines
Within the cluster configuration, we can specify multiple worker node types (e.g.,r-8xlargefor CPU-intensive tasks,g4dn-8xlargefor GPU-centric steps, and possibly others likem-16xlargefor memory-intensive operations). Crucially, by settingmin_workers=0for certain worker types, those machines only spin up when tasks actually require them, thereby keeping costs minimized when the resources are idle.
- Placement Groups & Gang Scheduling
To address tasks that require coordinated or simultaneous resource allocation—for instance, distributed training across multiple nodes, or large-scale ETL operations that need parallel execution—EKSRay supports Ray’s Placement Groups (PGs) and gang scheduling. These features ensure that a group of tasks can be delayed until all of the requested resources are allocated together, guaranteeing consistency and avoiding partial or staggered execution starts.
- Single “RayJob” Chaining
By chaining all the pipeline stages into a single RayJob, we gain:- Unified job logging and monitoring: All task steps and logs are consolidated in one place, simplifying debugging and performance analysis.
- Seamless autoscaling across stages: The system automatically provisions and deprovisions the exact resources each step needs, helping optimize both performance and cost.
- Easier prototyping-to-production transition: Most pipeline code remains unchanged when scaling from small datasets to very large ones—only the cluster configuration might need updates to accommodate increased resource demands.
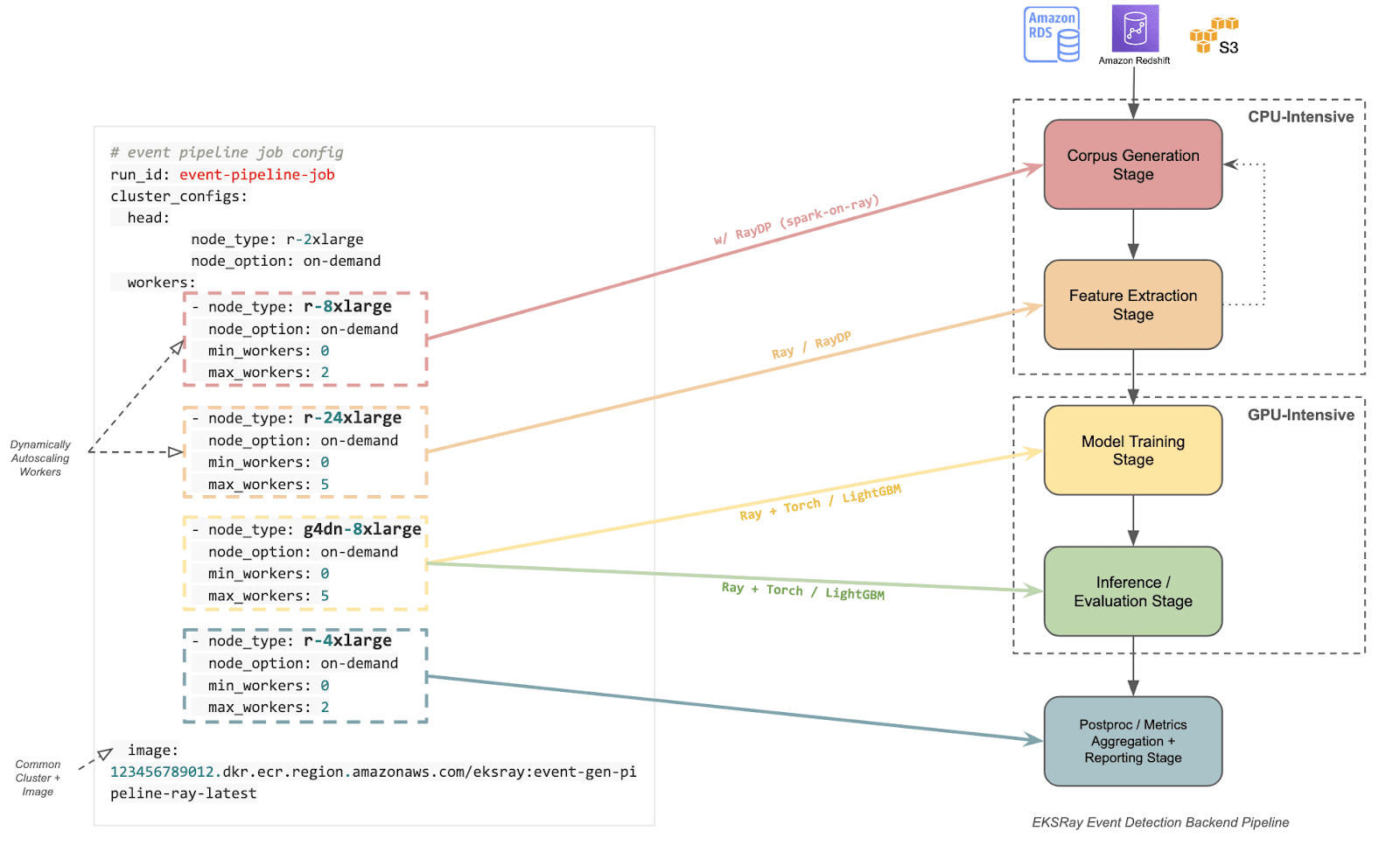
Example: Event-Detection Modelling Pipeline
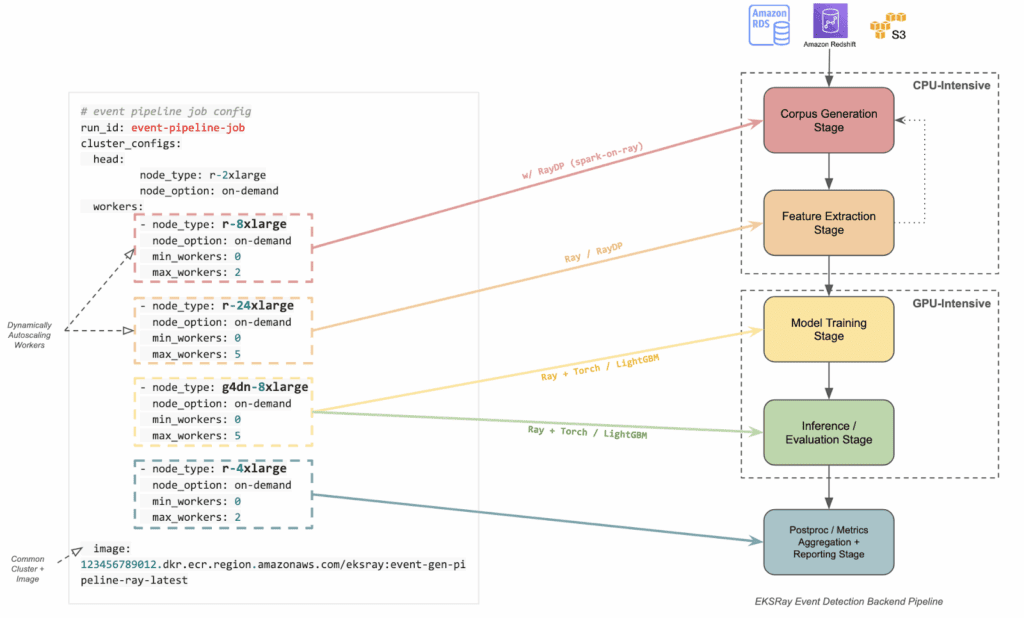
Referring to the illustration above, the Event-Detection Modelling pipeline encompasses multiple stages—metadata querying and processing, corpus generation, feature extraction, model training, inference, post-processing, and metrics reporting. Each stage exhibits different resource profiles:
- Metadata Querying / Corpus Generation: Lighter compute requirements, often more I/O bound, possibly dependent on cloud storage and database services.
- Feature Extraction: This stage is highly parallelizable, benefiting from scaling up CPU workers to handle large-scale data. Additionally, integrating RayDP (Spark-on-Ray) can enhance performance by leveraging Spark’s robust data processing capabilities within the Ray ecosystem, and for cross-platform compatibility.
- Model Training & Inference: Commonly GPU-intensive, especially if using advanced deep learning frameworks; can also be hybrid (CPU + GPU).
- Post-processing & Reporting: Typically CPU-focused, although can require memory-intensive steps depending on the size of generated outputs.
With a hybrid cluster that includes both CPU-focused and GPU-equipped worker nodes—and a single head node orchestrating tasks—we can dynamically spin up and scale only the portions of the cluster needed for each stage. Once these tasks complete, the autoscaler spins resources back down, keeping costs as low as possible.
Scalability & Future Developments
One of the key advantages of this approach is its adaptability to ongoing developments in the open-source ecosystem. Because EKSRay relies on foundational components like KubeRay, EKS, Ray Core, and the EKSRay CLI, any improvements in these areas translate directly to enhanced capabilities for the platform. As these tools continue to mature, we anticipate:
- Greater efficiency in how Ray schedules resources and tasks across different node types
- More advanced autoscaling policies that further reduce cost and idle capacity
- Continuous refinements to the user experience in spawning clusters and managing RayJobs
Ultimately, our vision is for EKSRay to serve as a low-cost, high-performance, and highly extensible platform for large-scale distributed training, ETL, and beyond. The flexible dynamic autoscaling architecture described here represents a significant step toward realizing that vision.
For those interested in harnessing these capabilities, CMT’s MLOps or Data Science departments can facilitate setup with EKSRay in under an hour. Once onboarded, data science teams gain access to a platform that automates critical workflows, scales effortlessly to handle even substantially large data workloads, and minimizes costs by allowing us to perform all these tasks while only incurring base EC2 costs. As open-source components like Ray and KubeRay continue to evolve, EKSRay remains poised to incorporate new innovations, further enhancing its robust, high-performance ecosystem for large-scale data science.